Export transactions from Santander
Published on ; updated on
Getting your transactions out of Santander’s online banking in a machine readable format like csv is far from trivial.
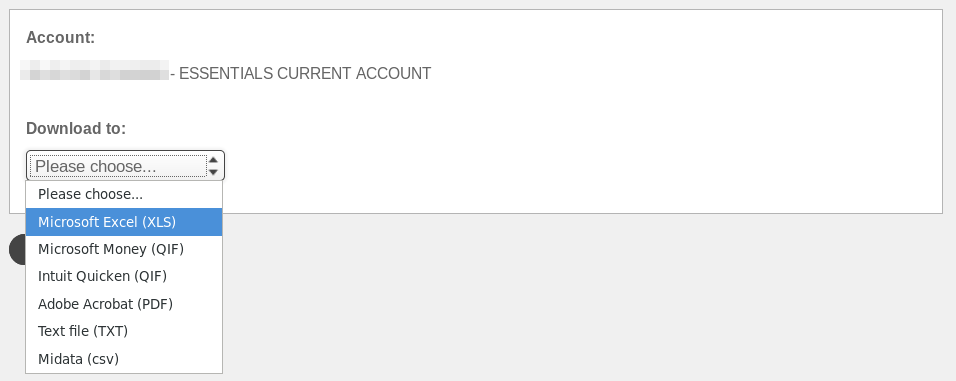
At first this seems like a lot of options, but most of them are useless:
“Midata (csv)” gives a semicolon-separated(!) file with only three transactions (out of 50+). It seems that these correspond to the two deposits and one cash withdrawal I’ve had, but all the cashless payments are absent. Additionally, the two deposits have their description masked with asterisks.
“Microsoft Excel (XLS)” indeed gives a file with an xls extension, but that extension has nothing to do with the file’s contents.
% file 2018-03-03.xls
2018-03-03.xls: HTML document, ISO-8859 text, with very long linesIt’s an html file consisting of a giant badly-formatted table, littered with FONT tags.
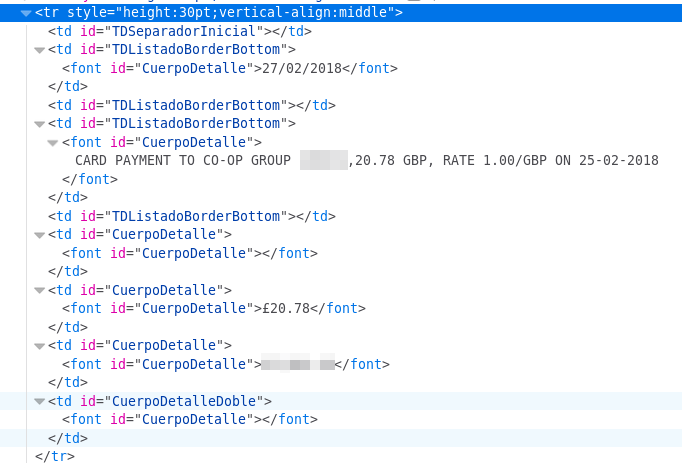
I thought that I could extract the data with htmltab, but it only recognizes the date column, not sure why.
Someone who goes by the name Infernus published a Ruby script to extract the data from the html file. The script, however, does not distinguish between the “money in” and “money out” columns in the html table, and so a ₤100 deposit and a ₤100 payment/withdrawal look exactly the same in the output file.
“Microsoft Money (QIF)” and “Intuit Quicken (QIF)” give exactly the same file, and that file cannot be parsed with Finance::QIF and this script, resulting in an “Unknown header format” error.
The only robust options to export the transactions seems to be through their txt file format, which looks like this:
From: 01/01/2018 to 03/03/2018
Account: XXXX XXXX XXXX XXXX
Date: 03/03/2018
Description: CARD PAYMENT TO STAGECOACH BUS,4.40 GBP, RATE 1.00/GBP ON 01-03-2018
Amount: -4.40
Balance: XXXX
...There are some peculiarities in the format, of course, like the Latin1 encoding and the use of non-breaking spaces as a separator, but all in all it can be easily parsed. Here’s a Perl script to convert Santander’s text format to the tab-separated value format (tsv).
#!/usr/bin/perl
use warnings;
use strict;
# The input file is encoded in iso-8859-1.
open my $f, "<:encoding(iso-8859-1)", $ARGV[0]
or die qq{Could not open $ARGV[0]: $!};
binmode(STDOUT, ":utf8");
# Field and record separators.
$, = "\t";
$\ = "\n";
# Field names, for both the input and the output file.
# The order is arbitrary and determines the order of the
# columns in the output file.
my @names = qw(Date Description Amount Balance);
# Mapping from column names to column numbers.
my %pos;
@pos{@names} = (0..$#names);
# Print the tsv header.
print @names;
my @this;
while (<$f>) {
if (my ($name,$value) = /^(\S+):\s*(.*?)(\s*|\x{A0}.*)$/g) {
if ($name eq 'Date' and @this) {
print @this;
@this = ();
}
if (defined $pos{$name}) {
$this[$pos{$name}] = $value;
}
}
}Update (2018-06-05)
The script is now updated to deal with an inconsistency in Santander’s txt format. Within the same file, I see some records that include the currency
Amount:<A0>-3.00<A0>and some that don’t
Amount:<A0>-41.28<A0>GBPIt’s scary to imagine how they generate this file.