How much space does an 8-bit integer occupy in C and Haskell?
Published on
How much space does an unsigned 8-bit integer occupy in C and Haskell?
Neither the C99 standard nor the Haskell2010 standard specifies such low-level details, so the answer could in theory be anything. To have something to work with, let’s make the following assumptions:
- architecture: x86-64
- ABI/calling conventions: System V
- C compiler: GCC 6.3
- Haskell compiler: GHC 8.0
C
In C, the unsigned 8-bit integer type is called uint8_t.
It is defined in the header stdint.h. Its width is
guaranteed to be exactly 8 bits; thus, its size is 1 byte.
But how much space does it really occupy? That depends on two factors
- whether it is a function argument or return value, or a (local or global) variable
- whether it is part of an array or struct
Function arguments and return values
According to the AMD64
System V ABI, the first 6 integer arguments are passed via registers
and the rest are passed on the stack. If a function returns a single
integer value, it is passed back in a register. Since the integer
registers are 64-bit wide, when a uint8_t value is passed
in a register, it effectively occupies 8 bytes.
To illustrate, consider this function:
uint8_t plus(uint8_t a, uint8_t b) {
return a+b;
}GCC generates the following code:
lea (%rsi,%rdi,1),%eax
retq The two arguments are passed in the 64-bit registers
%rsi and %rdi. Although the result is written
to a 32-bit register %eax, it is part of the 64-bit
register %rax, and the other 32 bit of that register cannot
be reused easily while %eax is occupied.
What about the arguments passed through the stack? The ABI dictates that their sizes, too, are rounded up to 8 bytes. This allows to preserve stack alignment without complicating the calling conventions.
Example:
uint8_t plus(uint8_t a, uint8_t b, uint8_t c,
uint8_t d, uint8_t e, uint8_t f,
uint8_t g) {
return a+g;
}translates into
mov %edi,%eax
add 0x8(%rsp),%al
retq We see that the g argument is 8 bytes below the stack
boundary, (%rsp). These whole 8 bytes are dedicated to our
tiny int.
When uint8_t’s are part of a struct or similar, they
occupy one byte each. Curiously, if the struct is 16 bytes or smaller,
the uint8_t’s will be packed into registers!
struct twobytes {
uint8_t a;
uint8_t b;
};
uint8_t plus(struct twobytes p) {
return p.a+p.b;
}compiles into
mov %edi,%eax
movzbl %ah,%eax
add %edi,%eax
retq Both bytes are passed inside %edi, and the intermediate
1-byte %ah register is used to take them apart.
Local and global variables
Like function arguments, local variables can reside in registers or on the stack. But unlike function arguments, local variables are not constrained by calling conventions; the compiler can do whatever it wants.
When an 8-bit local variable is stored in a register, it effectively occupies the whole 64-bit register, as there is only one 8-bit “subregister” per general-purpose register (unlike in x86).
What happens to the local uint8_t variables stored on
the stack? We can compile this test program to find out:
uint8_t plus(uint8_t a, uint8_t b) {
volatile uint8_t c = a+b;
return c;
}add %edi,%esi
mov %sil,-0x1(%rsp)
movzbl -0x1(%rsp),%eax
retq The volatile keyword is needed to force the compiler to
store the local variable c on the stack rather than in a
register. As we see, c is stored at
-0x1(%rsp), so 1 byte is enough here. This is because there
is no alignment requirement for 8-bit integers. The same is true for
global variables.
Haskell
In Haskell, the unsigned 8-bit integer type is called
Word8. Its canonical module according
to the standard is Data.Word, but in GHC, it is
originally defined in GHC.Word and then re-exported from
Data.Word.
Word8 is a boxed type. The space occupied by every boxed
type in Haskell consists of two parts: the header and the payload. Here
is a helpful picture from the GHC
wiki:
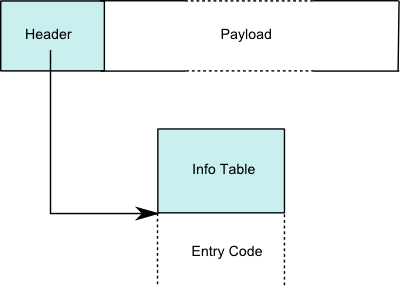
Note that stuff on the bottom of the picture — the info table and the entry code — is read-only static data shared among all instances of the given type and even across multiple copies of the same program, so we don’t count it towards the space occupied by a value.
The header is a structure that (on x86-64) normally consists of 8 bytes — a pointer to the entry code for the object.
The value of our byte is stored in the payload. But how exactly?
Let’s look at the definition of Word8 in GHC.Word:
-- Word8 is represented in the same way as Word. Operations may assume
-- and must ensure that it holds only values from its logical range.
data Word8 = W8# Word#
-- ^ 8-bit unsigned integer typeWord# is an unboxed machine-word-sized unsigned integer,
i.e. a 64-bit integer for x86-64.
In total, a Word8 lying around occupies 16 bytes. When
computing with Word8’s inside some kind of inner loop, they
will normally be unboxed into Word#’s and passed around in
8-byte registers or in 8-byte cells on the (Haskell) stack — more or
less like in C.
Thus, during computation, Haskell is not that different from C. But
what about storage? Can multiple Word8’s be packed together
densely?
TwoBytes
Say, we need a structure, TwoBytes, consisting of two
Word8’s. We intend to use it as a key and/or element type
in a large dictionary, so we’d like to keep it as compact as possible.
(Note that Data.Map already adds
a 48 bytes overhead per key/value.)
If we declare TwoBytes in the most naive way
data TwoBytes = TwoBytes Word8 Word8the structure will occupy 56 bytes! TwoBytes would
consist of a header (8 bytes) and a payload consisting of two pointers
(8 bytes each), each pointing to a Word8 (16 bytes
each).
A more efficient way to declare TwoBytes is
data TwoBytes = TwoBytes {-# UNPACK #-} !Word8
{-# UNPACK #-} !Word8This makes the fields strict and unpacked, so that the two bytes are
stored directly in TwoBytes’s payload. This occupies 24
bytes — “only” 12 bytes per Word8. Compared to a single
Word8, we see some economy, but it only amortizes the
header. No matter how many Word8’s we put together, the
size won’t get below 8 bytes per Word8.
To pack bytes together, we can use an unboxed vector:
data TwoBytes = TwoBytes {-# UNPACK #-} !(Vector Word8)To see how much memory this structure occupies, we need to see the
definition of Vector
and the underlying ByteArray:
-- | Unboxed vectors of primitive types
data Vector a = Vector {-# UNPACK #-} !Int
{-# UNPACK #-} !Int
{-# UNPACK #-} !ByteArray -- ^ offset, length, underlying byte array
data ByteArray = ByteArray ByteArray#The runtime representation of ByteArray# is a pointer to
the StgArrBytes structure defined in
includes/rts/storage/Closures.h:
typedef struct {
StgHeader header;
StgWord bytes;
StgWord payload[FLEXIBLE_ARRAY];
} StgArrBytes;The space required for a ByteArray# is 8 bytes for the
header, 8 bytes for the length, and the payload, rounded up to whole
words (see stg_newByteArrayzh in
rts/PrimOps.cmm) — so 8 bytes in our case, 24 in total.
The size of Vector, therefore, is 8 bytes for the
header, 16 bytes for the offset and length (needed to provide O(1)
slicing for vectors), 8 bytes for the pointer to the
ByteArray#, and 24 bytes for ByteArray#
itself; total of 56 bytes.
This is the opposite of the previous definition in that the
representation is asymptotically efficient, requiring 1 byte per
Word8, but the upfront cost makes it absolutely impractical
for TwoBytes.
Even if we cut out the middleman and used ByteArray
directly:
data TwoBytes = TwoBytes {-# UNPACK #-} !ByteArray… it would only get us to 40 bytes.
The most frugal approach for the case of two bytes is to define
data TwoBytes = TwoBytes {-# UNPACK #-} !Word(16 bytes) and do packing/unpacking by hand. This is a rare case
where a Haskell programmer needs to write code that a C compiler would
generate (recall two bytes packed into %edi) and not the
other way around.
If GHC provided a Word8# unboxed type, we could use the
earlier defined
data TwoBytes = TwoBytes {-# UNPACK #-} !Word8
{-# UNPACK #-} !Word8which would still occupy 16 bytes but be more conventient to work
with than a single Word. But that’d require a major change
to the compiler, and it’s probably not worth the hassle.
Summary
In both C and Haskell, a byte-sized integer occupies 8 bytes when it is actively worked upon (i.e. kept in a register) and 1 byte when many of them are stored in an array/vector.
However, when storing single Word8’s or small structures
like TwoBytes, Haskell is not as memory-efficient.
Primarily this is because idiomatic Haskell relies heavily on pointers
and everything is word-aligned.